乱码恢复指北
tl;dr:需要恢复乱码的访客可使用此类服务,或参考下面的例子与您需要恢复的乱码进行对照。
本文尝试对各种乱码的特征进行描述,并给出在各种编码中转换的一些方案。
记得原来看到过一张很简明的关于乱码的解释图,不过找不到了。有那张图的同学希望能告诉我一下。
2020/02 更新:Misaka00251 有找到那张图发在群组里,这里把它转译为文本放在末尾了。
什么编码?
这里我们讨论最常见的几个:Windows-1252(CP-1252)、GBK(以及 GB2312。GBK 范围稍大且兼容 GB2312,故取此)、Big5(大五码,常用于繁体中文)、Shift-JIS(常用于日文)。
长什么样?
以下列举出各种编码的特征。不同编码服务于不同的文字类型,因此其字符表中的内容也不同,乱码的特征也不同。幸运的是,(半角)英文字符和数字通常不受影响,它们在这些编码中转换的时候不会出现问题。
Windows-1252
Windows-1252 大概是最好区分的。它是拉丁字母的编码,所以被以 Windows-1252 解码的结果是没有汉字的。只有以下内容:
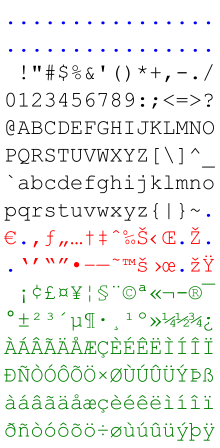
(图源:Wikimedia Commons)
{kind=link}
另外,它与 ISO 8859-1 非常相似,也常有人把 Windows-1252 当作 ISO 8859-1 宣告。WHATWG 的标准中是要求把以 ISO 8859-1 宣告的文本当作 Windows-1252 编码来解析的。
举几个乱码的例子:
巡音ルカ(GBK) ->ѲÒô¥ë¥«(Windows-1252)巡音ルカ(UTF-8) ->巡音ルカ(Windows-1252)
GBK 和 Big5
这两种编码的结果比较像。因为其中编码的多是汉字,所以其它编码的字符以它们解码得到的常是「汉字的集合(非常用汉字占绝大部分)」(UTF-8 -> GBK、UTF-8 -> Big5 或 GBK <-> Big5),或是一堆不可识别字符和 tofu(方块)。例如:
我能吞下玻璃而不伤身体。(GBK) ->扂夔迒狟產薛奧祥夼旯极﹝(Big5)我能吞下玻璃而不傷身體。(Big5) ->и唰]U良τぃ端ō砰C(GBK,errors='ignore')- (这里使用了繁体的原因是「伤」字在 Big5 中无编码。)
我能吞下玻璃而不伤身体。(UTF-8) ->鎴戣兘鍚炰笅鐜荤拑鑰屼笉浼よ韩浣撱(GBK,errors='ignore')我能吞下玻璃而不伤身体。(UTF-8) ->賢銝餌銝隡方澈雿(Big-5,errors='ignore')
(这句话的来源,参见这里。)
顺便也用ルカ测试一下:
巡音ルカ(Shift-JIS) ->弰壒儖僇(GBK)巡音ルカ(Shift-JIS) ->J(Big5,errors='ignore')(可见的严重信息损失)
Shift-JIS
刚才说过了,这是给日文用的编码。因此,被以 Shift-JIS 解码的结果自然是日文居多,更明显的特征是有相当多的半长文字。英文同样不受影响。
举几个乱码的例子:
巡音ルカ(GBK) ->蟾。髻ウ繝ォ繧ォ(Shift-JIS)巡音ルカ(UTF-8) ->ムイメ・・ォ(Shift-JIS,errors='ignore')巡音ルカ(BIG5) ->ィオュオヌ・ヌC(Shift-JIS)
UTF-8
UTF-8 由于其目标远大(说白了,什么字都有,再带上 emoji),所以以其解码的结果中什么都有可能出现,无论是汉字、日文,还是符号。甚至有时候可以幸运地凑出组合字符。
袩褉懈胁械虂褌(GBK) ->Приве́т(UTF-8)啶ㄠぎ啶膏嵿い啷(GBK) ->नमसत(UTF-8,errors='ignore')
如何在各种编码中转换?
最方便的方案是用类似这样的网站(或者 r12a 的编码转换工具 ,感谢 RainSlide 推荐)。如果没有的话,Python 也行。
转换编码,可以这么做(Python 3 环境):
"以 ENCODING_A 编码的字符串".encode('ENCODING_A').decode('ENCODING_B')Python 3 会把原来的字符串以 ENCODING_A 编码,转换至 Unicode 字符集的 byte,再以 ENCODING_B 解码。如果编码或解码出问题的话(例如码表里没有这个字符),会报 UnicodeEncodeError 或 UnicodeDecodeError。如果想忽略错误的话,在相应的地方加入参数 errors='ignore' 即可,像是:
"以 ENCODING_1 编码的字符串".encode('ENCODING_A', errors='ignore').decode('ENCODING_B', errors='ignore') # 暴力编码+解码而如果要解码二进制字符串,可以这么做:
b'\xaa\xbb\xcc'.decode('ENCODING')那么锟斤拷、烫烫烫、屯屯屯和锘锘锘呢?
In a nutshell: 「锟斤拷」是连续的 UTF-8 容错字符以 GBK 解码的结果。
b'\xef\xbf\xbd\xef\xbf\xbd'.decode('gbk') # -> '锟斤拷'「烫烫烫」和「屯屯屯」是 MSVC 填充未初始化内存的字节以 GBK 解码的结果。
b'\xcd\xcd\xcd\xcd\xcd\xcd'.decode('gbk') # -> '屯屯屯'
b'\xcc\xcc\xcc\xcc\xcc\xcc'.decode('gbk') # -> '烫烫烫'「锘锘锘」则是 UTF-8 BOM 以 GBK 解码的结果。
b'\xef\xbb'.decode('gbk') # -> '锘'(怎么都特么是 GBK 的锅)
参考来源:
所以...为什么水了这篇文?
下载的一些 VOCALOID 歌曲(其中不小的一部分来自网易云)的元数据标签是 GBK 编码的,Rhythmbox(以及 Lollypop 还有 kid)会以 Windows-1252 来解码,于是播放列表的显示就爆炸了。
反正我是真切地记住了 ³õÒô¥ß¥¯ (Windows-1252) => 初音ミク (GBK)。看这乱码,多整齐啊。
附注:常见编解码错误表
| 名称 | 举例 | 特点 | 产生原因 |
|---|---|---|---|
| 「古文码」 | 鎴戣兘鍚炰笅鐜荤拑鑰屼笉浼よ韩浣撱 | 大部分为不认识的古文,夹杂日韩文 | 以 GBK 方式读取 UTF-8 编码的中文 |
| 这个在上文中提到过。被误以 GBK 和 Big-5 解码经常会得到看起来像中日韩文字的结果。运气好的时候能全部或大部分恢复。 | |||
| 「口字码」 | ��������������� | 大部分字符为方块 | 以 UTF-8 的方式读取 GBK 编码的中文 |
| 这个方块是对不能显示的字符的替换符号,码位是 0xFFFD。通常来说内容是不能恢复的了。 | |||
| 「符号码」 | 巡音ルカ | 大部分字符为符号 | 以 ISO8859-1 方式读取 UTF-8 编码的中文 |
| (见下条。) | |||
| 「拼音码」 | ѲÒô¥ë¥« | 大部分字符为头顶带有各种声调符号的字母 | 以 ISO8859-1 方式读取 GBK 编码的中文 |
| 上两条指的就是上文中提到的 Windows-1252 的例子。因为多是可见符号,显示上也没什么问题,所以很多时候可以完全恢复。 | |||
| 「问句码」 | 我能吞下玻璃而不伤身?? | 字符串长度为偶数时正确,字符串长度为奇数时最后的字符变为问号 | 以 GBK 方式读取 UTF-8 编码的中文(然后保存),然后又用 UTF-8 格式再次读取 |
| 由于编码特性问题,用 GBK 保存 UTF-8 文档可能会有内容损失。至于那俩问号...只是问号而已,最后的一个字是找不回来的。 | |||
| 「锟拷码」 | 锟斤拷锟斤拷锟斤拷锟斤拷锟斤拷 | 全中文字符,且大部分字符为「锟斤拷」这几个字符 | 以 UTF-8 方式读取 GBK 编码的中文,然后又用 GBK 格式再次读取 |
| 这个在上文也提到过。显然在这种案例下,内容是不可恢复的了。 | |||
其实,其实,这里最优雅的方案应是 Musicbrainz Picard(或类似产品)。